Distill the visual generation pathway's reasoning knowledge into text-only inference — no image generation at test time, yet outperforming the generative teacher.
Unified multimodal models generate intermediate "visual thoughts" (VTs) via diffusion during reasoning, but this costs ~14× latency. We discover that rendered VT pixels are not load-bearing — yet the generation pathway encodes valuable reasoning knowledge. Visual-OPSD distills this knowledge into text-only inference via cross-modal on-policy self-distillation.
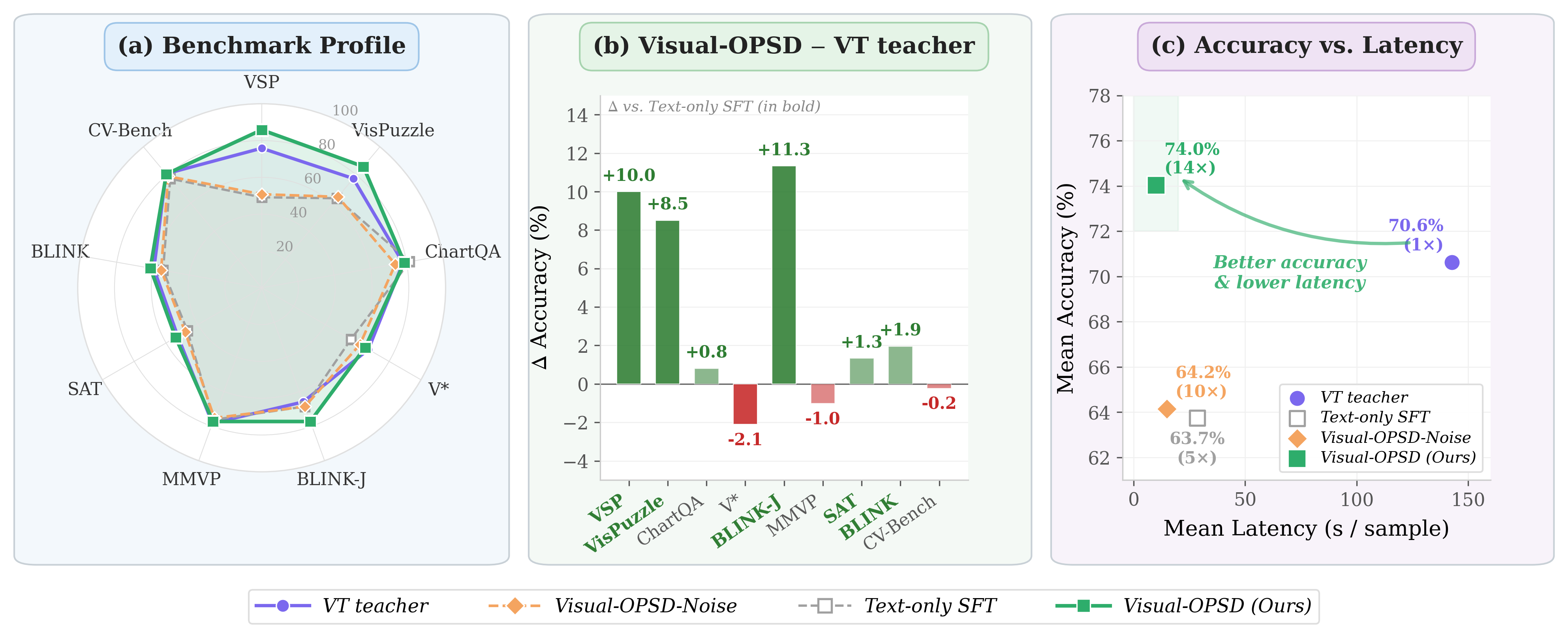
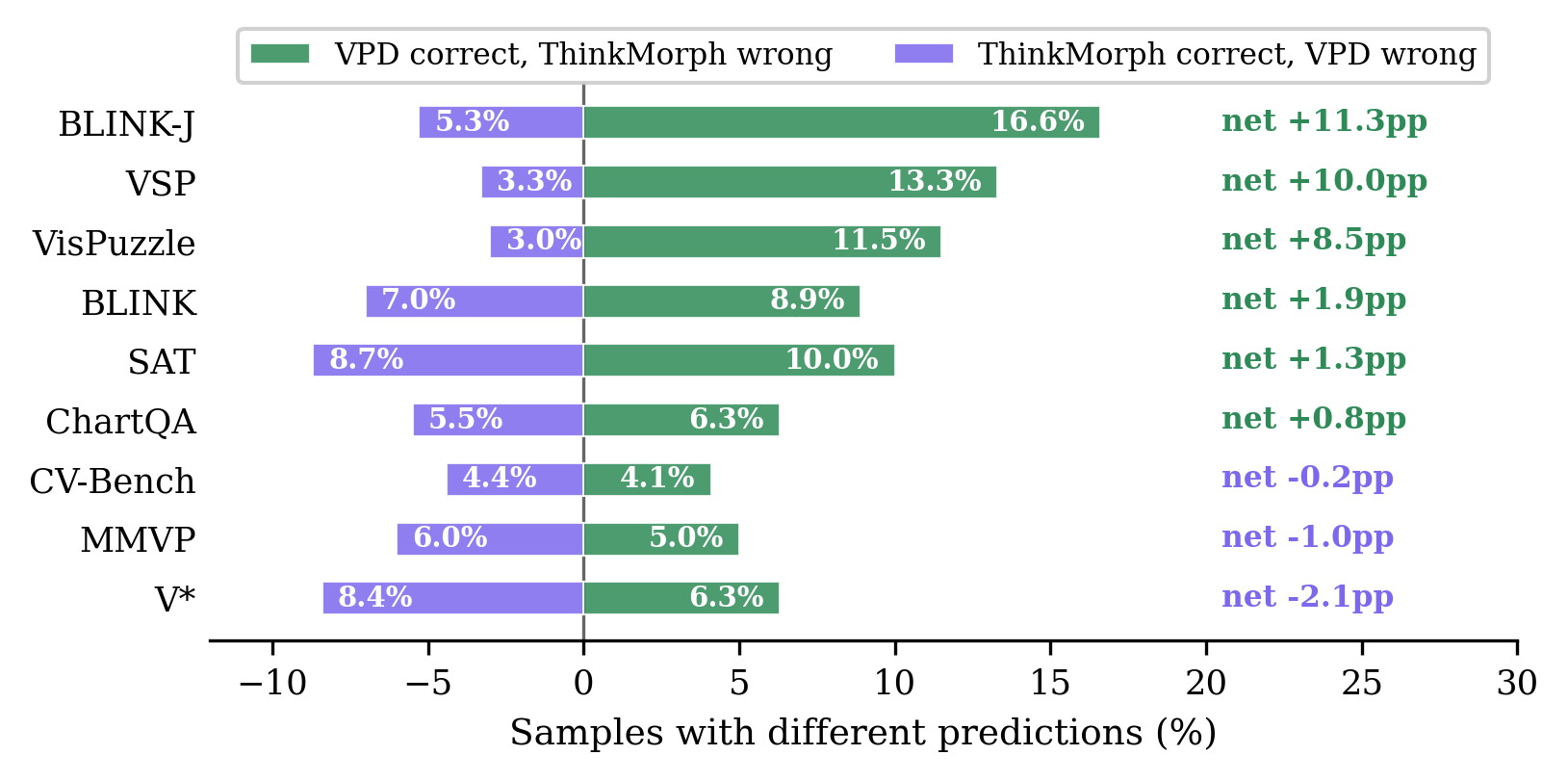
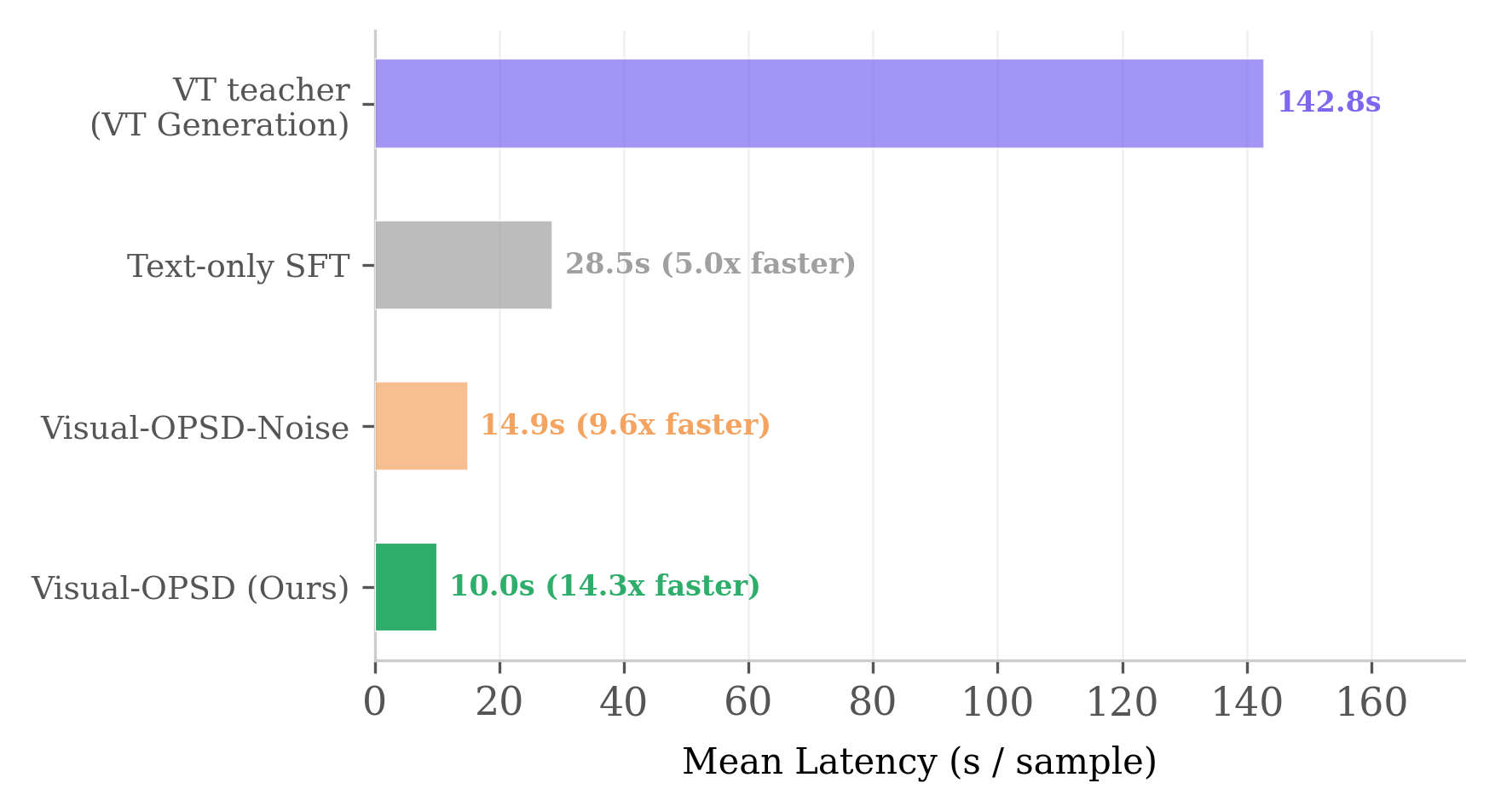
Visual-OPSD matches its VT-generating teacher at 14× lower latency. (a) Visual-OPSD (green) ≥ teacher (purple) on 6/9 tasks. (b) Per-task Δ: VSP +10.0, VisPuzzle +8.5, BLINK-J +11.3. (c) Pareto: 74.0%/10.0s vs. 70.6%/142.8s.
Through controlled interventions on ThinkMorph, we reveal a surprising gap: rendered VT pixels contribute little to accuracy, yet the generation pathway encodes substantial distributional knowledge measurable via KL divergence (4.64 nats/token).
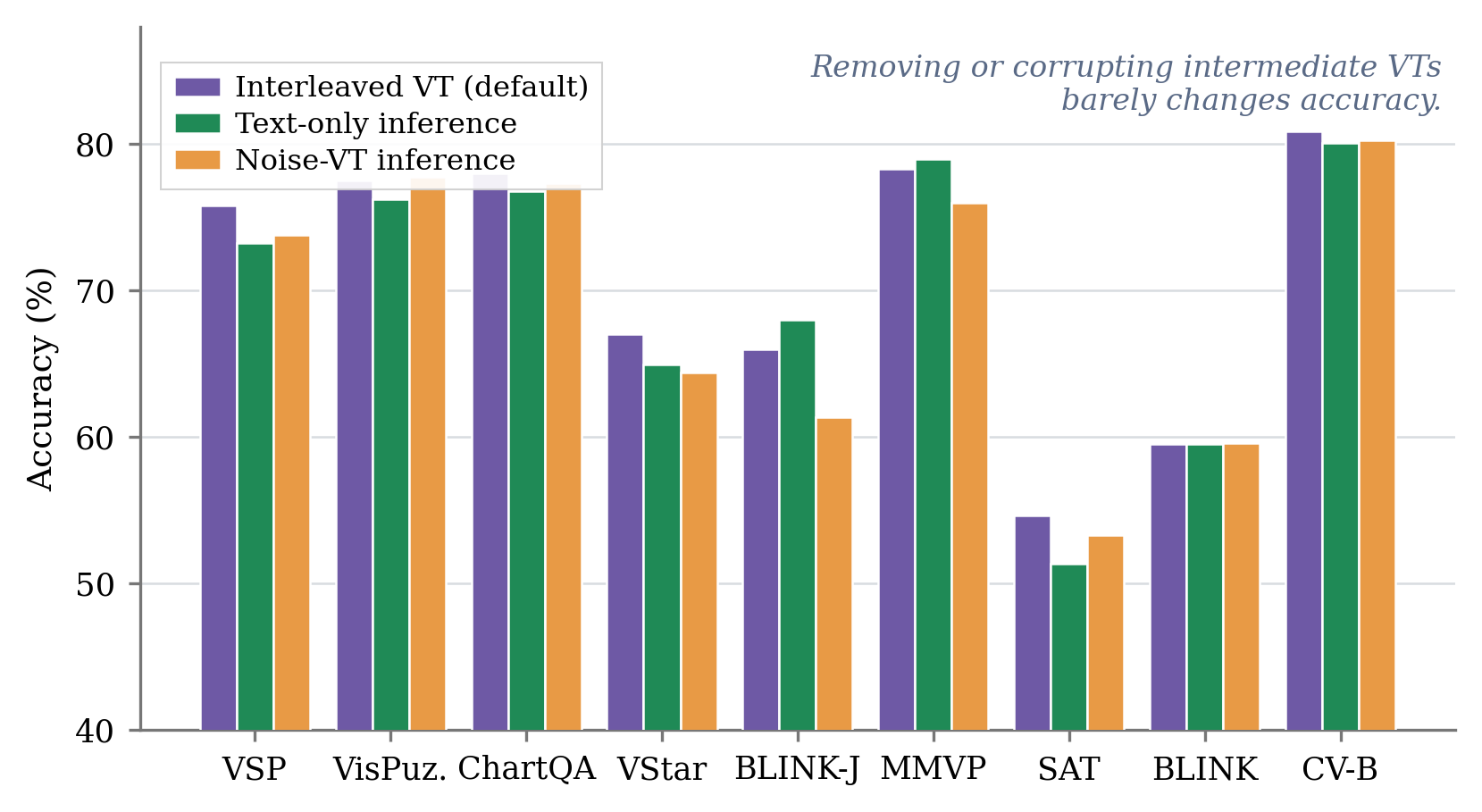
Removing or corrupting intermediate VTs at inference leaves accuracy largely unchanged across all nine benchmarks. The rendered pixels are not load-bearing.
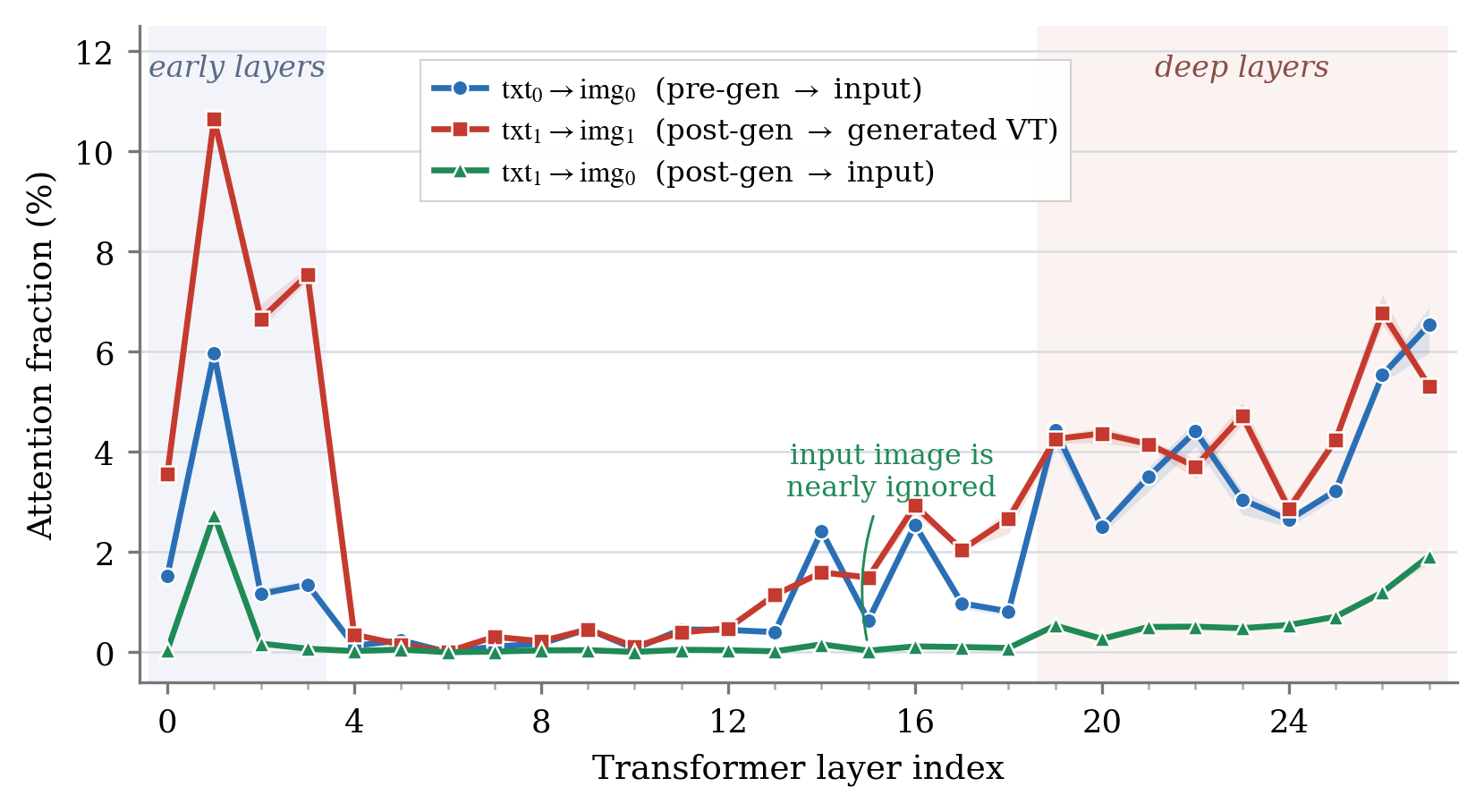
Once generated, a VT dominates subsequent reasoning attention regardless of its content — even Gaussian noise receives the same attention allocation.
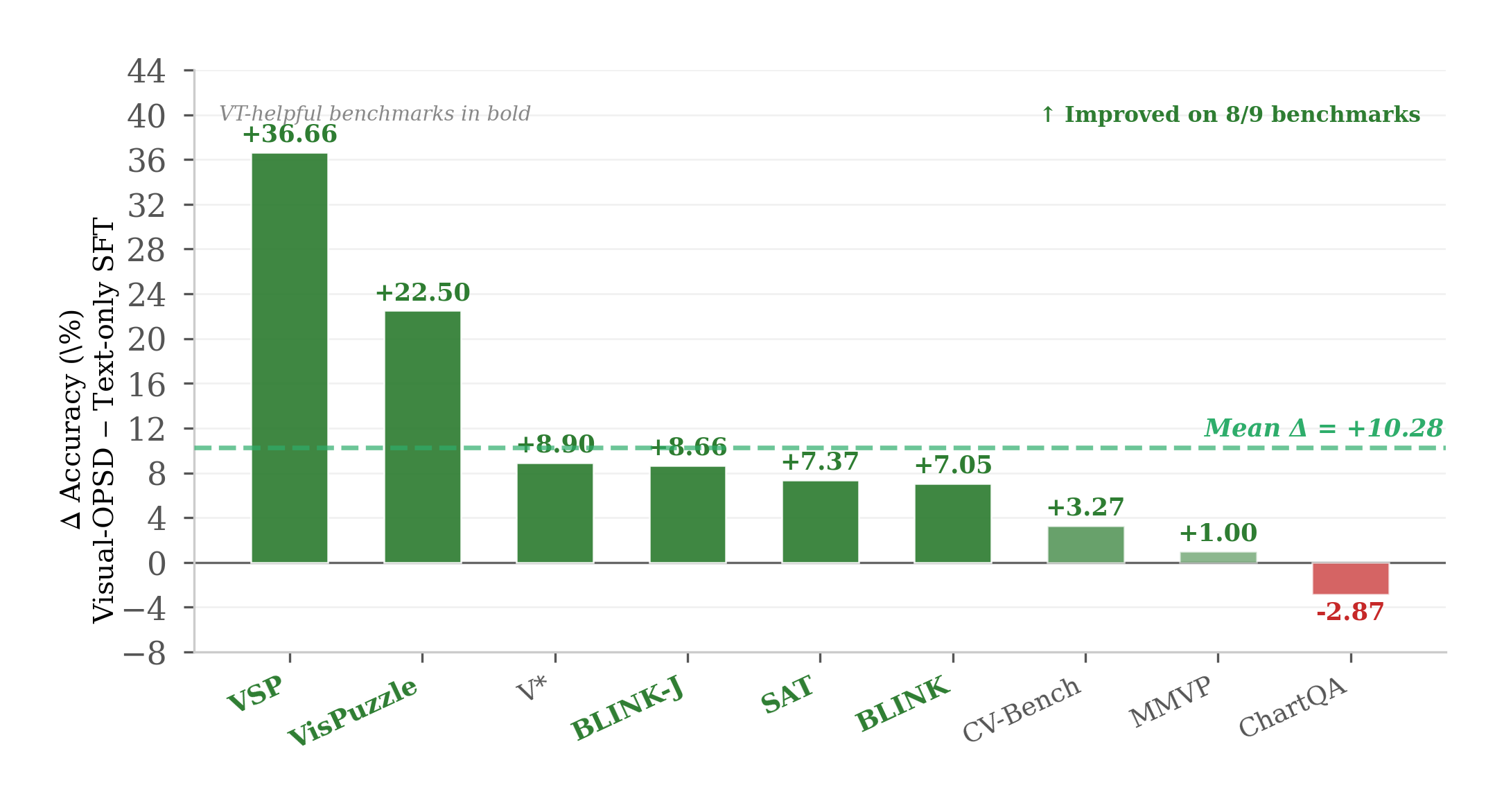
VT Information Quality Scaling. The decisive gap (+10.28pp vs +0.40pp) confirms knowledge originates from VT semantic content, not regularization.
First OPSD framework bridging the generation–understanding gap within a unified multimodal architecture. Teacher and student share identical weights.
Eliminates 50-step diffusion at test time: 10.0s vs 142.8s per sample. No architectural changes or extra parameters needed.
Distribution-level distillation de-noises VT artifacts: the student outperforms its generative teacher on 6/9 benchmarks (+3.40pp average).
Student samples its own completions, keeping training on-policy. Image-skip injection prevents collapse into generation mode.
Gaussian-noise control (+0.40pp vs +10.28pp) and KL gap-closing analysis (58.4% closure) confirm semantic VT content is the knowledge source.
Dominates same-scale VLMs on spatial tasks: VSP 85.8% vs InternVL3.5-8B 8.2% and Qwen3-VL-8B 22.0%.
Visual-OPSD exploits the information asymmetry between generation and understanding pathways within a single unified multimodal model. No external teacher, no architectural changes.
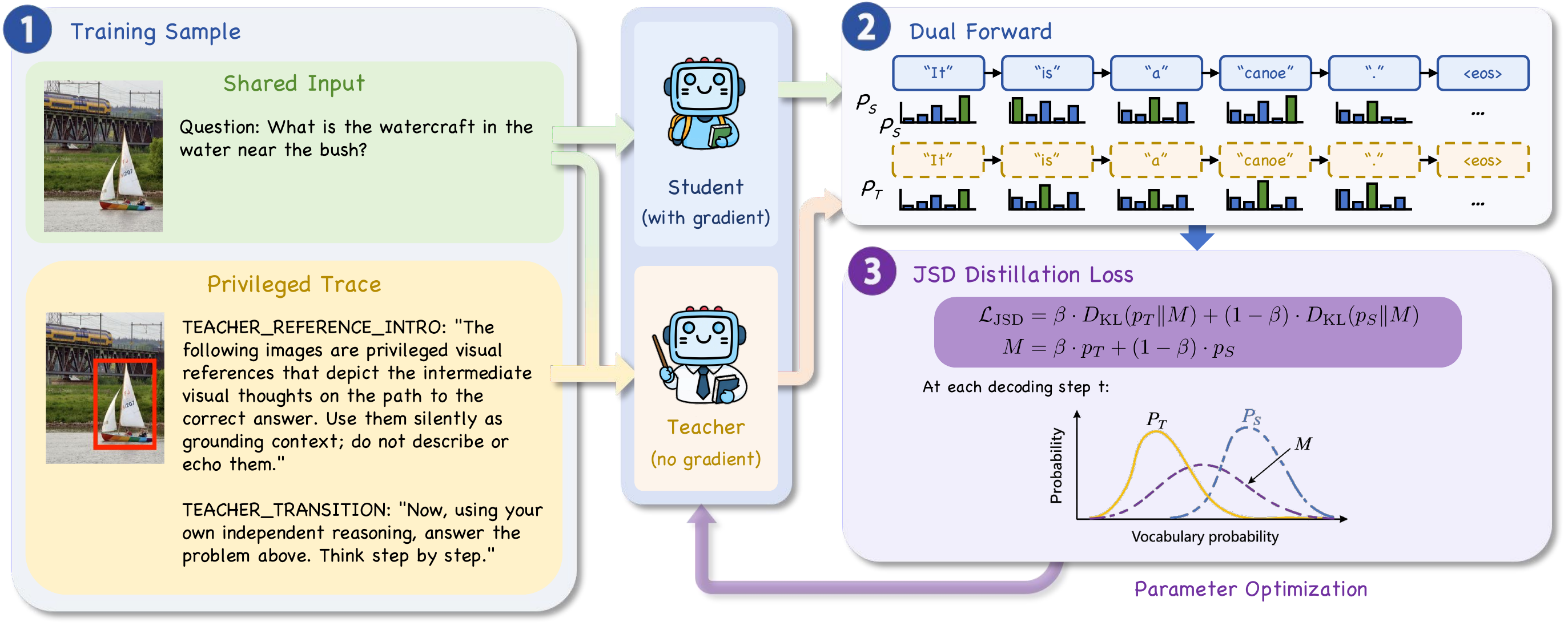
Overview of Visual-OPSD. A student πθ(·|CS) sees only [sys, ViT(x), q], while an EMA teacher πθ̄(·|CT) additionally receives privileged VTs. Both rescore the student's on-policy completion via per-token JSD. At inference, the student runs text-only — 14.3× faster, +3.40pp over teacher.
Measure the distributional gap between VT-conditioned and question-only contexts. Confirms 4.64 nats/token of distillable generation knowledge.
Student generates completions from its current policy. Image-skip injection handles <image_start> tokens, keeping sampling on-policy without generation mode collapse.
Per-token JSD with pointwise clipping (τ=0.05) and top-K=256 truncation. EMA teacher (α=0.995) provides stable, progressively updated targets.
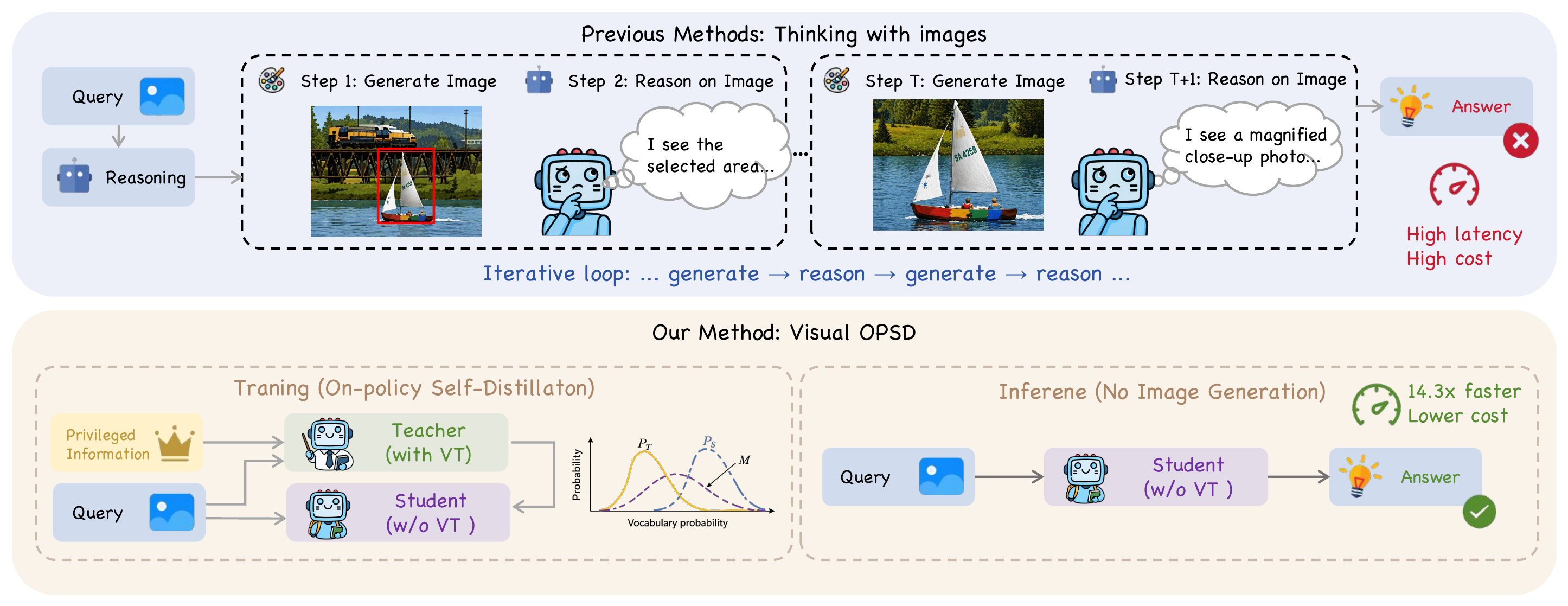
Prior interleaved visual CoT vs. Visual-OPSD. (Top) Previous methods iterate generate-then-reason, rendering each VT via 50-step diffusion at high cost. (Bottom) Visual-OPSD distills the generation pathway into a text-only student, yielding +3.40pp at 14.3× speedup with no image generation at inference.
Visual-OPSD achieves the best average accuracy among open 7–8B models while running 14.3× faster than ThinkMorph.
| Method | VSP ↑ | VisPuzzle ↑ | ChartQA ↑ | VStar ↑ | BLINK-J ↑ | MMVP ↑ | SAT ↑ | BLINK ↑ | CV-Bench ↑ | Avg ↑ | Lat. (s) ↓ |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Vision-Language Models (VLMs) | |||||||||||
| InternVL3.5-8B | 8.17 | 34.75 | 76.26 | 68.59 | 71.33 | 76.33 | 45.33 | 59.60 | 81.99 | 58.04 | – |
| Qwen3-VL-8B | 22.00 | 37.00 | 82.55 | 84.29 | 68.66 | 77.66 | 54.00 | 69.43 | 85.63 | 64.58 | – |
| GPT-4o | 33.50 | 43.75 | 76.34 | 61.78 | 72.67 | 84.67 | 28.00 | 60.28 | 75.61 | 59.62 | – |
| GPT-5 | 57.33 | 78.00 | 80.85 | 71.73 | 77.33 | 86.33 | 73.30 | 69.86 | 85.46 | 75.58 | – |
| Unified Multimodal Models (UMMs) | |||||||||||
| Janus-Pro-7B | 0.00 | 33.50 | 43.08 | 38.22 | 50.67 | 63.33 | 22.00 | 38.51 | 67.83 | 39.68 | – |
| BAGEL-7B | 0.83 | 35.00 | 61.82 | 55.49 | 67.33 | 70.33 | 44.67 | 47.66 | 76.03 | 51.02 | – |
| ThinkMorph | 75.83 | 77.50 | 78.00 | 67.01 | 66.00 | 78.33 | 52.67 | 59.49 | 80.86 | 70.63 | 142.8 |
| Ours | |||||||||||
| Text-only SFT | 49.17 | 63.50 | 81.66 | 56.02 | 68.67 | 76.33 | 46.63 | 54.39 | 77.37 | 63.75 | 28.5 |
| Visual-OPSD-Noise | 50.83 | 64.50 | 73.77 | 61.70 | 68.66 | 75.33 | 48.00 | 55.49 | 79.09 | 64.15 | 14.9 |
| Visual-OPSD (Ours) | 85.83 | 86.00 | 78.79 | 64.92 | 77.33 | 77.33 | 54.00 | 61.44 | 80.64 | 74.03 | 10.0 |
| Δ vs. ThinkMorph | +10.00 | +8.50 | +0.79 | −2.09 | +11.33 | −1.00 | +1.33 | +1.95 | −0.22 | +3.40 | 14.3× |
| Δ vs. Text-only SFT | +36.66 | +22.50 | −2.87 | +8.90 | +8.66 | +1.00 | +7.37 | +7.05 | +3.27 | +10.28 | 2.9× |

We present cases where ThinkMorph's generated VT images actively harm reasoning, while Visual-OPSD avoids these failure modes by reasoning directly from the original input.




VT generated after committing to A visually reinforces the error, creating a self-reinforcing feedback loop.
Directly compares both options against original input, correctly identifying contour alignment.




VT blending artifacts at patch boundaries mask spatial discontinuities that reveal incorrect placement.
Identifies correct spatial continuity by analyzing alignment of visual elements directly from the original.


VT bounding box isolates the racket from full-body context, causing reasoning from a spatially impoverished representation.
Integrates holistic body cues — foot positioning, torso orientation, and shoulder angle — to determine correct direction.



Round 0 reasoning contradicts itself; VT resolves internal ambiguity toward the wrong spatial direction.
Consistent reasoning without VT-induced self-contradiction. Correctly assesses chair movement direction.
We introduced Visual On-Policy Self-Distillation (Visual-OPSD), the first On-Policy SelfDistillation framework that operates across modalities within a single unified multimodal model. Visual-OPSD provides direct evidence that the visual generation pathway of UMMs encodes reasoning knowledge into the model’s representations beyond what the generated pixels themselves contain, and that this knowledge can be distilled into the text understanding pathway via on-policy JSD without any architectural changes. The Visual-OPSD student outperforms its generative teacher on 6/9 benchmarks (+3.40pp on average) while achieving a 14.3× inference speedup, and substantially exceeds same-scale dedicated VLMs on spatial reasoning tasks. The Visual-OPSD-Noise control (+0.40pp vs. +10.28pp) and the post-distillation KL closing analysis (58.4% vs. 3.5%) together confirm that the transferred signal specifically requires the generation pathway’s semantic content, ruling out regularization as the primary mechanism.
@article{li2026visual,
title={Visual-OPSD: Cross-Modal On-Policy Self-Distillation for Efficient Unified Multimodal Reasoning},
author={Li, Pengyu and Gao, Zhitao and Zhang, Lingling and Huang, Muye and Li, Yuanming and Xu, Fangzhi and Liu, Jun},
journal={arXiv preprint arXiv:2606.18974},
year={2026}
}